Investigating intermittent bugs#
Stb-tester is ideal for reproducing and understanding intermittent, hard-to-reproduce bugs in your set-top-box or in your broader “system under test” (which could include your broadcast systems, back-end servers, network, etc).
In all of the case studies below, it only took me 1 or 2 hours to write each test. We’ll see some of Stb-tester’s features and techniques that we can use to streamline the investigation of intermittent defects.
Case study: BT multicast IPTV#
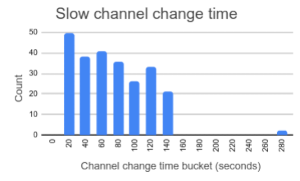
In 2013, BT (British Telecom) launched streaming TV channels, broadcast using IP multicast. With only weeks to go before launch (a hard deadline motivated by the upcoming premier league matches) we had an intermittent defect: When you changed channel to an IP channel, it would sometimes take a long time to tune — but only for 2% of channel changes.
It turned out that there were 2 separate bugs contributing to this problem. Fixing the first bug improved the defect rate from 2% to 1% of channel changes. To confidently distinguish between a 1% defect and a 2% defect, you need over 1,000 test runs. Without this data, it would be impossible to say whether the first bug-fix had helped at all! After we fixed both bugs, we needed thousands of test-runs more, to gain statistically significant confidence that the bug was gone.
Depending on the steps needed to reproduce the bug, 1% can be well below the error rate of manual testing. If you are using automated tests, you need confidence that any test failures are the actual defect you’re looking for, not “false positives” (unrelated bugs or spurious errors in the test infrastructure itself). Stb-tester provides a video recording of every test-run so every test failure could be checked by a human.
We made the test-script fail (assert) if the channel-change took longer than a certain threshold, so that we could easily find the slow channel-changes among the thousands of test-runs.
How many test-runs do you need?#
After a bug-fix has been deployed and you have seen 10 successful test-runs, can you be confident the bug is fixed? 100? 1,000? It depends on how often the bug used to occur.
Chi-squared test#
The Chi-squared test is a statistical tool to compare the defect rate of two different systems (such as your set-top-box “before” and “after” a bug-fix). There is a useful online calculator at https://www.evanmiller.org/ab-testing/chi-squared.html:
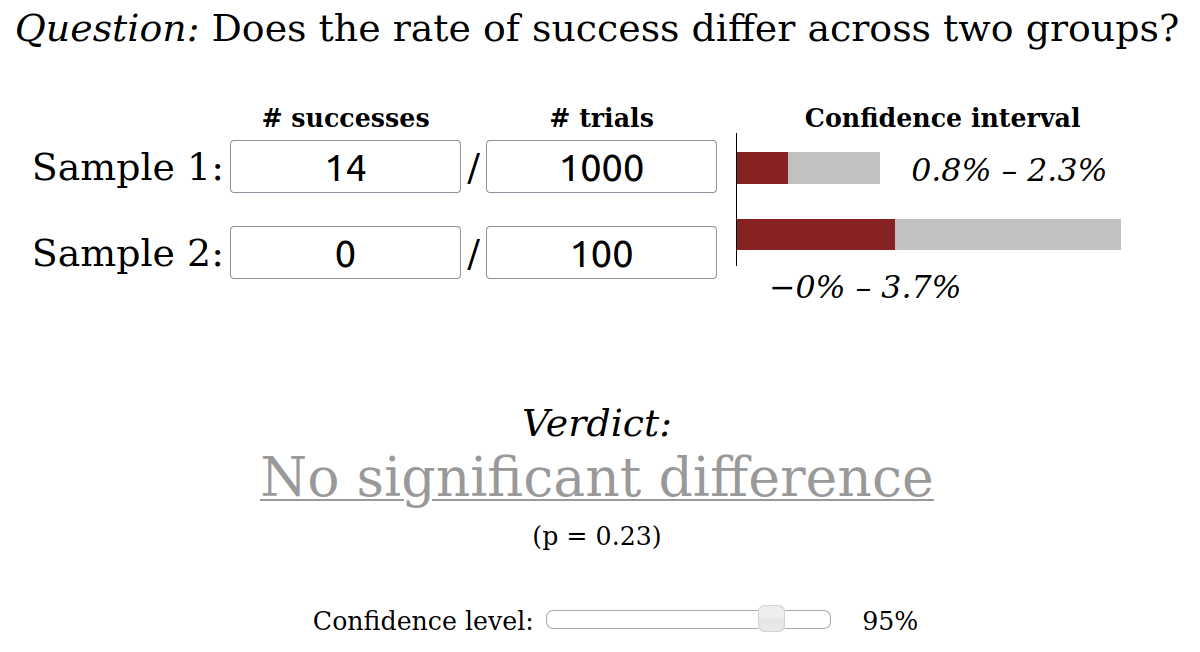
In the calculator above, “Sample 1” was before we applied the bug-fix to our set-top-box: We ran the test 1,000 times, and it found the bug 14 times. It doesn’t matter which way you define “success” (14/1,000 vs 986/1,000) as long as you are consistent in both samples.
“Sample 2” shows our test results after we applied the bug-fix: We ran the test 100 times, and haven’t seen the bug yet. The calculator shows that we don’t have enough trials (test-runs) to tell whether the “bug-fix” actually worked. The bug could still be there, and we just haven’t hit it yet.
You can play with the numbers in the calculator to get a rough idea of how many test-runs you’ll need.
Confidence intervals#
Stb-tester’s results view shows a 95% confidence interval for each “pass” or “fail” count.
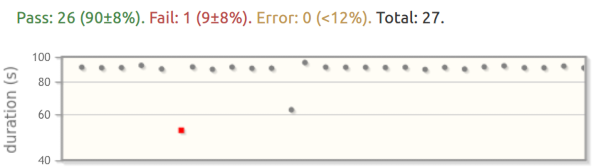
What does a “95% confidence interval” mean? The defect has some probability of occurring — the true probability. We don’t know what that probability is, so we are trying to measure it. The more trials we run, the more confident we are that the probability we measured is close to the true probability. In the screenshot above, there is a 95% chance that the true failure rate is between 1% and 17% (9±8%). More test-runs will give a narrower interval.
Stb-tester uses the Wilson score confidence interval.
Validity of these statistical tests#
The above statistics are only valid if the following assumptions are true:
All the test-results in view must be the same test:
The same test script.
The same system-under-test (the same set-top-box, with the same software version).
The bug must be random.
For example, a bug that only happens at midnight is not random — no amount of testing during the daytime is going to find it.
Video: Checking test results#
Stb-tester’s test-results interface is designed to streamline the “triage” process of checking test failures. You can view and compare up to 2,000 test-runs on a single page. In this short video (3 minutes), I show how I checked the results for a test that was failing 5% of the time because the set-top-box was ignoring some remote-control signals.
Stb-tester provides frame-accurate synchronisation between the video and the logs from your test script. See Interactive log viewer.
Case study: Using preconditions to discard false positives#
At a different time, I worked on another intermittent bug: The set-top-box wouldn’t display the channel logo watermark (“digital on-screen graphic” or “DOG”) after rebooting. I wrote a simple Stb-tester script to reproduce this defect:
1import stbt, mainmenu, channels, power
2
3def test_that_the_on_screen_id_is_shown_after_booting():
4 channel = 100
5 mainmenu.close_any_open_menu()
6 channels.goto_channel(channel)
7 power.cold_reboot()
8 assert channels.current_channel() == channel
9 assert stbt.wait_for_match("on-screen-id.png")
After running this test 50 times, we had 5 failures:
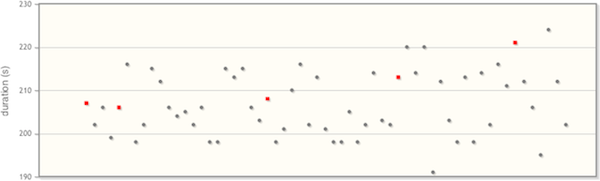
It takes me 2 minutes tops to verify that each of those 5 failures (the red dots) really is the defect we’re interested in, thanks to Stb-tester’s great triaging UI: I can see a screenshot where each test failed, and I can scrub through a video recording of the entire test-run if I need more detail.
What about 1,000 runs?
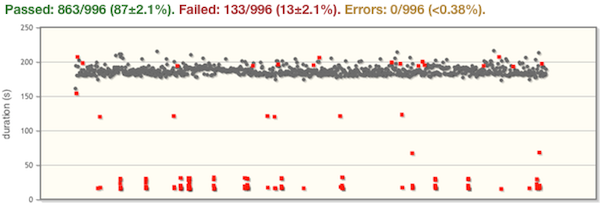
It turns out that running the same test script 1,000 times against a consumer-grade set-top box will reveal some interesting behaviours. Some of these failures might be genuine defects in the system-under-test; some of them are merely that the test script doesn’t handle every eventuality. I wrote the test script in a hurry to investigate this particular defect, so it isn’t super robust to things like a dialog popping up that says “I couldn’t connect to the network”. I don’t care if the IT team scheduled some maintenance over the same weekend when I left this test running, and the network went down for a few minutes. All I want to know is: Is my defect real? What is its reproducibility rate? Or maybe: Has it really been fixed in the latest release?
So I take my test script and I add one line (line 6, highlighted below):
1import stbt, mainmenu, channels, power
2
3def test_that_the_on_screen_id_is_shown_after_booting():
4 channel = 100
5
6 with stbt.as_precondition("Tune to channel %s" % channel):
7 mainmenu.close_any_open_menu()
8 channels.goto_channel(channel)
9 power.cold_reboot()
10 assert channels.current_channel() == channel
11
12 stbt.wait_for_match("on-screen-id.png")
Now when I run the test script 1,000 times I get results like this:
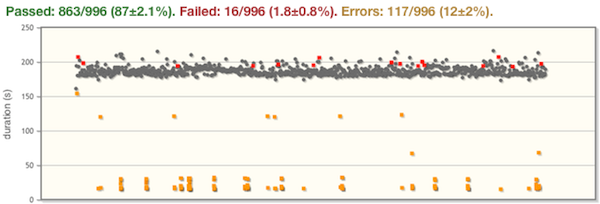
Much better! Now I can ignore all the yellow results (which I call test errors) and focus on investigating the few red results (test failures). To learn more about test failures, test errors, and stbt.as_precondition, read on.
Test failures vs errors#
A test fails when it detects a defect in the system-under-test.
A test error is a problem with the test script or test infrastructure.
Test failures#
wait_for_match raises a UITestFailure exception if it doesn’t find a match. (Specifically it raises a MatchTimeout, which is a subclass of UITestFailure.)
Stb-tester’s other core functions also raise UITestFailure exceptions when the system-under-test’s behaviour doesn’t match the expected behaviour.
You can also use assert in your test scripts.
Stb-tester considers all of these test failures, and reports them in red.
Test errors#
Stb-tester will treat any other exception raised by your Python script as a
test error (reported in yellow). These include mistakes in your Python
script (SyntaxError, TypeError, ValueError), as well as the
PreconditionError raised by stbt.as_precondition.
You can use the interactive filter in Stb-tester’s results interface to hide test errors and other results you aren’t interested in.
Preconditions#
Most test scripts will perform a series of operations to get the system-under-test into a certain state, and then check the behaviour that is the purpose of the test.
Sometimes it is useful to treat failures that happen during those initial setup
operations as test errors. For example when you are investigating a single
intermittent defect, as in the example above. In such cases, use
with stbt.as_precondition(): to turn test failures into errors.
But in more general soak and functional tests, it is better not to use stbt.as_precondition to hide potential defects. Write your test script so that it expects, and can correctly react to, every legitimate behaviour of the system-under-test. That way, any misbehaviour of the system-under-test will be flagged as a failure; problems with the test infrastructure itself will still appear as errors.